
Monetizing datasets
Thanks to Jeff Lau and Amadeus Pellice for their thoughts and suggestions.
One of the most obvious business ideas is to monetize a dataset of information. Specifically, I break down this type of monetization into two distinct categories:
- Control access to the data.
- Free the data and build services around it.
Control access to the data
In this model the dataset is kept private and access to it is metered and monetized. It's also usually the case that users are forbidden via the terms of service from downloading and storing the entire dataset locally.
An example is what3words. They have split the surface of the Earth into 3-metre squares and generated a 3-word label for each such square (For example, archive.retract.searches maps to the São Bento metro station in Portugal). The rationale for this co-ordinate system is that it supposedly allows for more precise sharing of a location (vs postal addresses) in a human-friendly format (vs numerical geo-coordinates).
Altogether there are 37,324,800 squares that have 3-word labels. The company behind it have opted to provide a commercial API which maps from traditional geo-coordinates to 3-word labels and vice versa. Layered on top of their API are various tools for businesses to be able to leverage the API easily from within their existing online presences.
There are a number of issues I see with this business model.
First of all, if I'm building an app which needs to map 3-word labels to geo-coordinates or vice versa I'm going to want to cache the results I obtain from the API service locally, unless they change very often. This is so that I can reduce the lookup time in my app and thus provide a better experience for the end-user.
This idea of cacheing applies to most datasets that change infrequently. Cacheing is such a common engineering technique that even CPUs do it. It's why things like DNS cacheing exist despite the fact that DNS mappings can actually change (just not too often, which is why cacheing makes sense). The corollary is that cacheing is not good if the dataset can frequently change and/or is unpredictable - e.g. APIs which return the current weather, current market price of an asset, etc.
All in all: If your data very rarely or never changes, enabling others to redundantly copy it fully and/or partially makes the most sense from an efficiency point-of-view. Monetizing access to the data instead is a bad business model and will likely fail.
Going back to what3words, their data never changes, so one would be foolish not to cache it. Or better yet, download the subset of the data that matters and then just bundle that directly to users to avoid any API lookups in the first place. For instance, an app like Uber that only works in cities would only need geo-mapping for those cities' regions. Knowing the 3-word label that maps to a specific square in the Pacific ocean would be useless information. And for businesses that do need to deal with the full global coordinate space, their target audience is likely to be comfortable enough with traditional geo-coordinates. And do note that geo-coordinates lend themselves to numerical calculations whereas 3-word labels do not.
Now, onto discussing the other monetization strategy, where the underlying dataset is freely provided to all...
Free the data and build services around it
A great example of a publicy accessible database is the Ethereum blockchain. Anyone anywhere can fire up a server running Ethereum node software and download the entire blockchain, with all the transaction data from genesis until now. But this dataset is so large that there is ample opportunity for services to exist that contextualize and analyse this data for easier consumption. And indeed, they already do.
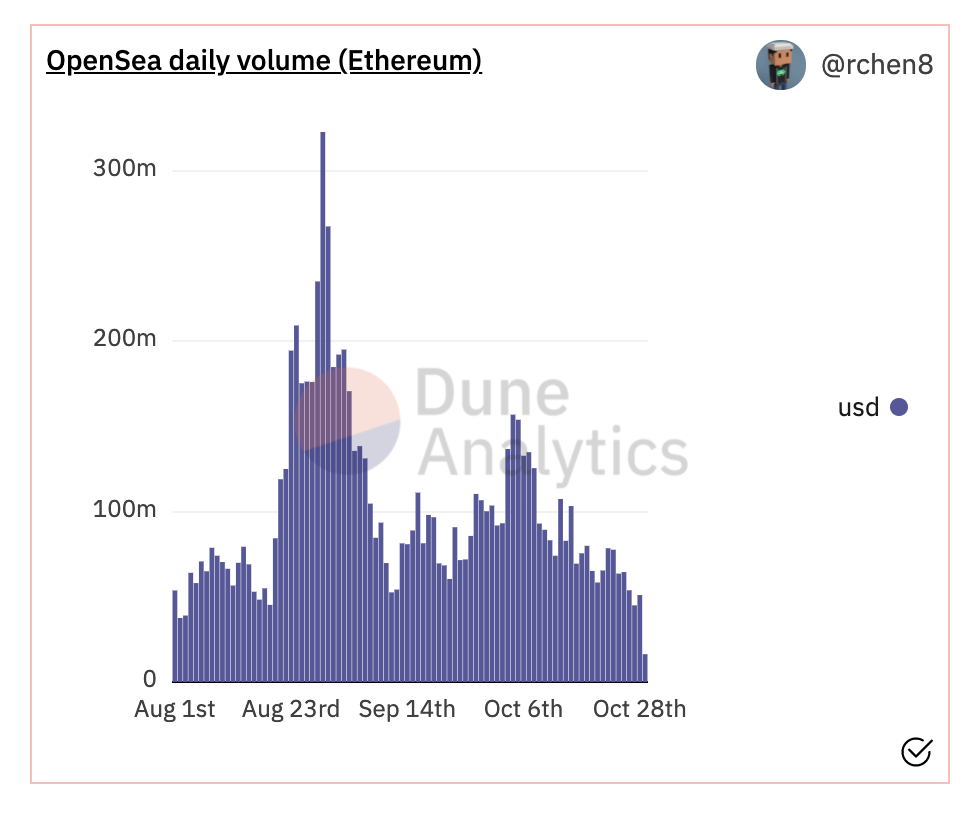
One could argue that what3words are also providing an add-on service on top of the existing public geo-coordinate "dataset". However the difference is that what3words don't provide any analytical data but rather just a once-generated mapping. Thus the add-on value is quite low.
This brings up the key point: To be able to successfully monetize a freely-available dataset you have to provide a high-enough-value add-on service.
Now let's consider the general compensation flow in such a monetization model.
If the data is generated automatically as a consequence of some activity - as in the case of the Ethereum blockchain - then it can be argued that all parties involved in the generation and analysis of the data are already appropriately compensated for their efforts.
But what if the data is curated?
Let's look at TripAdvisor. Its main value comes from community-contributed "advice" and ratings around the various travel objects (sights, hotels, tours, activities) listed. The users contributing to the site do so in the hope that others also do the same, i.e. reciprocal peer behaviour. Meanwhile, the company hosting the servers has sole access rights to the full dataset and thus has the sole ability to monetize it via various add-on services (e.g. bookings).
Due to its business model, users who contribute data to TripAdvisor arguably aren't being fairly compensated for the value they generate. But what if they could be? The problem is that the boilerplate involved in setting up such financial compensation systems is tedious and complex, which is likely why they haven't yet been done at such a large scale involving millions of contributors.
This is where blockchains can help¹. A dataset project would issue its own crypto token. Services utilising the dataset would freely use the data but need to stake the token to update the dataset with new information. Bad updates would cost them their stake ("bad" = rejected by the token holders via vote, "good" = accepted via vote).
Initially, the token could be distributed in a liquidity mining fashion, whereby contributors earn tokens for making good contributions (they would still need to stake tokens in order to make future updates). The distribution would last over a long enough duration in order to release the token supply gradually and disincentivize large market dumps. The need to stake to engage with curation and governance will drive token demand, especially as the dataset becomes more popular and critical to the apps which depend on it.
Effectively, token holders would be governing the project and curation of the data. This would be akin to democratic governance. The difference being that the governance permit that a user holds also happens to be a tradeable currency - unlike in the real world where your permit to vote is your government-created id that doesn't have a built-in monetary element.
¹ This post isn't intended to be a sales pitch for blockchains! I see them as the obvious solution to the problem of scaling per-contributor compensation in a fair manner.